當開始與許多廠商聯繫,
認識了越來越多人,
自然而然會累積許多名片。
要是未來希望能搜尋特定廠商的特定聯絡人呢?
我們可以在一開始拿到名片的時候,
就將名片上的資訊進行萃取,
並且依照辨識到的字串,依據字串內容預測其可能的欄位,
寫入excel表格或是資料庫。
這裡採用監督式學習演算法,
我們大約需要自己標註20張名片的資料集。
我們使用上一篇文章所使用的google client vision程式來進行處理,
# !/usr/bin/python
# coding:utf-8
from google.cloud import vision
import io
import os
import glob
credential_path = "cred.json"
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = credential_path
client = vision.ImageAnnotatorClient()
def extract_txt(file_path):
with io.open(file_path, 'rb') as image_file:
content = image_file.read()
image = vision.Image(content=content)
response = client.text_detection(image=image)
texts = response.text_annotations
return texts[0].description
for filepath in glob.iglob('*.png'):
print(filepath)
extract_str = extract_txt(filepath)
new_txt_file_name =filepath[0:-4] + '.txt'
new_txt_file_path = os.path.join('./txt_file',new_txt_file_name)
with open(new_txt_file_path, 'w', encoding='UTF-8') as f:
f.write(extract_str)
為了節省成本,圖片轉成文字的過程只進行一次,
我們將文字資訊存成txt檔案,以利於往後處理。
接著對文字檔案進行操作:
import glob
import csv
replace_string_list = [':',',','"',"'",' ','地址','email','電話','手機','tel','傳真','職稱','姓名','統一編號','LINE','line']
for filepath in glob.iglob('*.txt'):
# print(filepath)
with open(filepath, 'r' , encoding='UTF-8') as f:
content = f.read()
print(content)
for replace_string in replace_string_list:
content=content.replace(replace_string,'')
with open('train.csv', 'a+' , encoding='UTF-8') as csvfile:
fieldnames = ['content','label']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
content_list = content.split('\n')
for content_ele in content_list:
writer.writerow({'content': content_ele, 'label': ''})
剔除一些未來會影響字串預測的文字(可依據模型表現新增或修改),
我們將資料寫於csv,
自行進行標註以及加上Index。
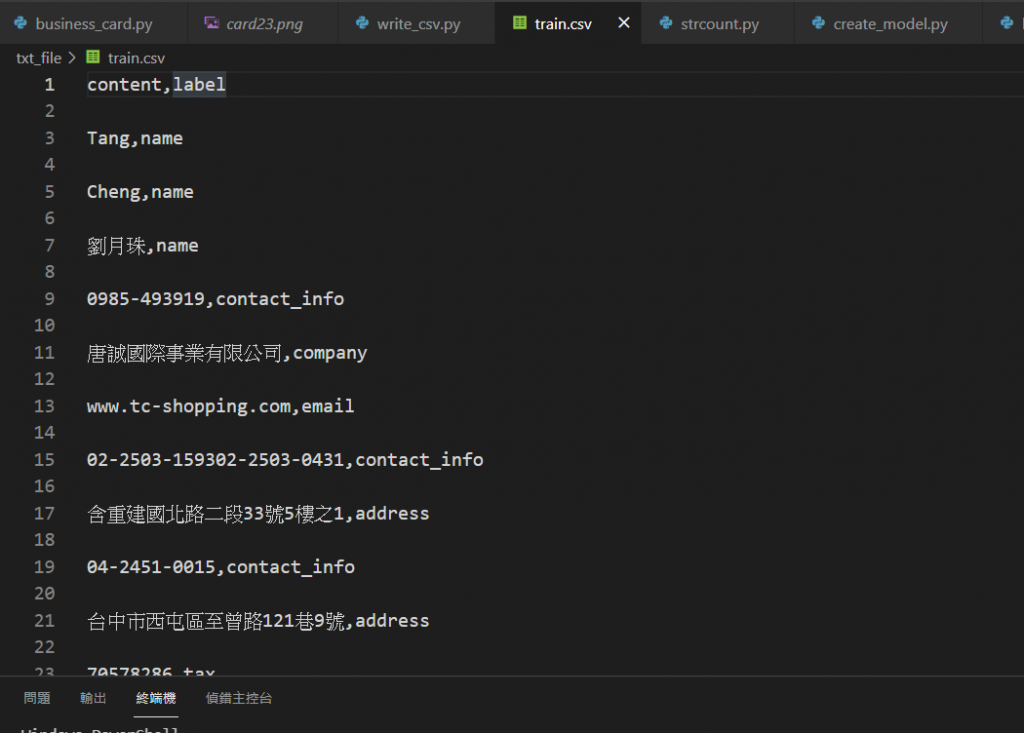
明天再進行文字特徵提取,建模以及預測。


 iThome鐵人賽
iThome鐵人賽